

HPCaaS & “Fun With [Compiler] Flags”: A Case Study with NASA’s FUN3D
Dr. Kevin G. McIver, Ph.D. | August 19, 2025
Forward
This post explores why HPC-as-a-service (HPCaaS) is a game-changer for engineers and one more way Corvid HPC stands out.
Most companies exist to solve a problem, and the more time engineers spend solving problems rather than dealing with all the requirements to be able to solve that problem, the more profit a company can realize. For some companies that means eschewing paid software licenses from Dassault or ANSYS, and instead opting for open-source or government-issued computational tools. These “free” tools can come at a cost though—optimizing them for specific tasks can be challenging and time consuming. In a vacuum, they may end up significantly slower than commercial codes and cost companies more in the long run.
Corvid HPC goes beyond simply offering cloud-based HPC. We optimize software packages like FUN3D to ensure companies get the fastest results at the lowest cost. Our FUN3D build is available directly to customers on our “uscloud.corvidhpc.com” portal after an appropriate amendment to the company’s NASA Software Usage Agreement to list Corvid HPC as their authorized third-party compute provider.
Why use HPCaaS?
Corvid HPC enables companies to avoid significant investments in CAPEX or labor costs by leveraging existing, expert-supported, fully-managed infrastructure. To understand what that means, let’s explore what it would take for a company to get started with digital engineering on an on-prem HPC and how compiling scientific software is often the Achilles heel for on-prem systems.
Digital engineering with HPC requires a comprehensive approach to address 6 key requirements leading to one outcome:
Robust Infrastructure: A reliable datacenter with consistent and sufficient power, cooling, and networking.
Sufficient Compute Resources: Access to ample CPU, GPU, FPGA, or other accelerator resources required by your computational software.
Scalable Storage: Adequate high-speed and high-volume storage solutions.
Secure IT Environment: A secure IT environment with appropriate accreditations for data protection and privacy.
User-Friendly Interface: A human-machine interface that enables effective resource sharing and interaction, preferably with graphics.
Optimized Software: Relevant and optimized software tailored to the specific compute resources.
Enable Digital Engineering: The ultimate goal is to solve the company's specific problems of interest.
On-Prem HPC
For on-prem systems, particularly those using pre-configured cluster solutions from the major hardware providers, they address requirements 2-3, but the company must provide their own solutions for 1 and 4-7. Once the hardware is installed in the datacenter, the company may need to install their own compute management stack (e.g., Nvidia’s AI Base Command formerly known as Bright Cluster Manager) which costs thousands of dollars per compute node per year on top of the cost of the hardware. These management solutions may or may not include ways to provide end users with remote access with a virtual desktop—many HPC deployments are CLI only, with at best X-forwarding to end user desktops.
Companies with on-prem HPC are often locked in to a particular size of cluster based on power and cooling availability, and will be stuck with either underutilized resources, or over utilized resources unable to meet peak demand during the busiest part of the year. The company must also provide an HPC admin and security team if they have compliance requirements (e.g., NQA-1, NIST 800-53, or CMMC)
Traditional Cloud HPC
For traditional cloud providers, requirements 1-3 can be addressed easily, for a price. There are even paid solutions that include an appropriate HPC management stack and virtual desktop access to answer 4 and 5, for more mark ups. Company provided system administration and security teams are still required to connect to these resources, which add to the cost compared to on-prem systems.
HPCaaS
Both on-prem and traditional cloud providers have a common gap that makes it difficult for engineers to be successful on their own, and that is requirement 6—providing optimized software to the engineers. Most companies have subject matter experts with deep understanding of the physics principles being examined in the scientific software they use, but treat that software (with limited exceptions) as a black box.
Most companies then, would really only like to think about item 7—something that on-prem and traditional cloud fail to provide.
That’s where Corvid HPC comes in!
Streamlining HPC: Simplifying Complex Workflows
At Corvid HPC, we're committed to simplifying your Digital Engineering with HPC journey. We provide pre-installed, working software environments for both licensed software (like ANSYS and StarCCM+) and NASA-supported open-source or government-use tools (including FUN3D, Pegasus, DPLR, and more).
The NASA codes that we have current agreements to support as a third-party compute resource are as follows: Overflow, FUN3D, Plot3D, Pegasus, DPLR, Chimera Grid Tools, and Vulcan.
FUN3D is a powerful, unstructured-grid Navier-Stokes solver. However, its setup and compilation can be time-consuming and complex. Compiling a single build (including the MPI) can take 40 minutes or more even when scripted. FUN3D
Doing optimization work on the builds can pay dividends in the long run—particularly when moving between different operating systems and major compiler revisions. Compiling FUN3D and other similar codes is complex because different flags can be turned on and different submodules can be built into the code for an engineer’s usage. Some compiled codes are more sensitive than others to OS version, package, or hardware upgrades—at Corvid HPC, we handle that testing for you for supported packages!
Compiling Scientific Software—An Arcane Art
FUN3D, has been extensively used by Corvid HPC and its parent company, Corvid Technologies in engineering consulting work for millions of CPU hours of CFD work. Due to this extensive usage, even small performance improvements can lead to significant savings across our HPC environment.
Once all the dependencies for FUN3D are properly selected and built with the same MPI / Compiler combination, a module file is made to make them easy for users to interact with by simply typing “module load nasa fun3d/14.1/a100” or “fun3d/14.1/h100” as appropriate depending on the binaries required for GPU acceleration.
Benchmarking codes also requires that we isolate away from storage I/O to ensure that results are representative of hardware and software performance—so for the purpose of these benchmarks, all cases are run in RAM disks (more on that feature in a future blog!), using the same input deck, the same compute node hardware, the same compute node quantity, running the same OS revision in this case, Rocky Linux 8.10.
The testing was far more extensive, but for brevity in the blog, let’s collapse the parameter space to cover three builds, one our “baseline” build from EL7, one from ~May 2024 when we switched to EL8, and one from October 2024 after OpenMPI 4.1.7 was released. OneMPI was not used for FUN3D because of incompatibilities with Zoltan and OneMPI in the present releases that caused segmentation faults during grid partitioning—despite being our current recommendation for users looking to compile code on Corvid HPC.

For the reader’s awareness, different build flags for component packages used in the compiling process not explicitly mentioned in this blog post can make large differences (10%+) in runtime for our benchmark case. By far, the biggest change seen in testing was the usage of a new MPI and GCC combination—so that is the primary parameter space of interest.
One additional variable was included--“(mapping)” --which is the addition of the flags “--map-by L3cache --bind-to L3cache” to the mpirun executable call in the submit script.

Figure 1: Elapsed time @ 2000 iterations for the 8 x od2 test builds. Note that for the EL7 build, the parenthetical indicates the host OS.
Migrating from EL7 to EL8 with the baseline build presented unexpected challenges for our AMD Milan nodes. The "baseline" EL7 build experienced significant slowdowns in the EL8 environment, particularly during the initial Zoltan partitioning step. Despite presenting with the same hardware utilization (100% load on all CPU cores, and similar RAM usage) the code did not make any progress and cycled at a significantly reduced rate.
The current thinking is that AMD's chiplet architecture introduced additional complexities not well handled with the GCC 5.4.0 / OpenMPI 4.1.3 combination. Despite the initial EL8_14.1_A build being slower than its EL7 counterpart, careful optimization, including mapping and binding to L3cache domains, significantly improved performance.
While newer software versions are often enticing, it's crucial to assess the impact of updates. The EL8_14.1_B build using OpenMPI 4.1.7 offered negligible performance gains over 4.1.6, highlighting the importance of targeted optimization.
By understanding these differences and implementing effective strategies, we can maximize performance and efficiency in complex computational environments.
The same slowdowns were not seen on our AMD Genoa CPUs from the od3 partition (5 nodes / 480 cores used in testing):

Figure 2: Elapsed time @ 2000 iterations for the 5 x od3 test builds. All builds run on Rocky Linux 8.10—note the much smaller range covered on the X-axis compared to the above graph.
In this build case, the mapping to L3cache domains had almost no effect, and the EL7 build showed almost no slowdown when used on EL8. This suggests that the slow down seen on AMD Milan is a particular sensitivity of the older GCC / OpenMPI combination to the architecture not found in the AMD Genoa CPUs. The EL8_14.1_B build is still ever so slightly slower than the El8_14.1_A build consistent with the od2 results.
To quantify the performance gains from AMD Milan to AMD Genoa, we introduced a normalized metric:

From there, a percentage metric is derived by dividing both values by the performance of the AMD Milan CPUs:
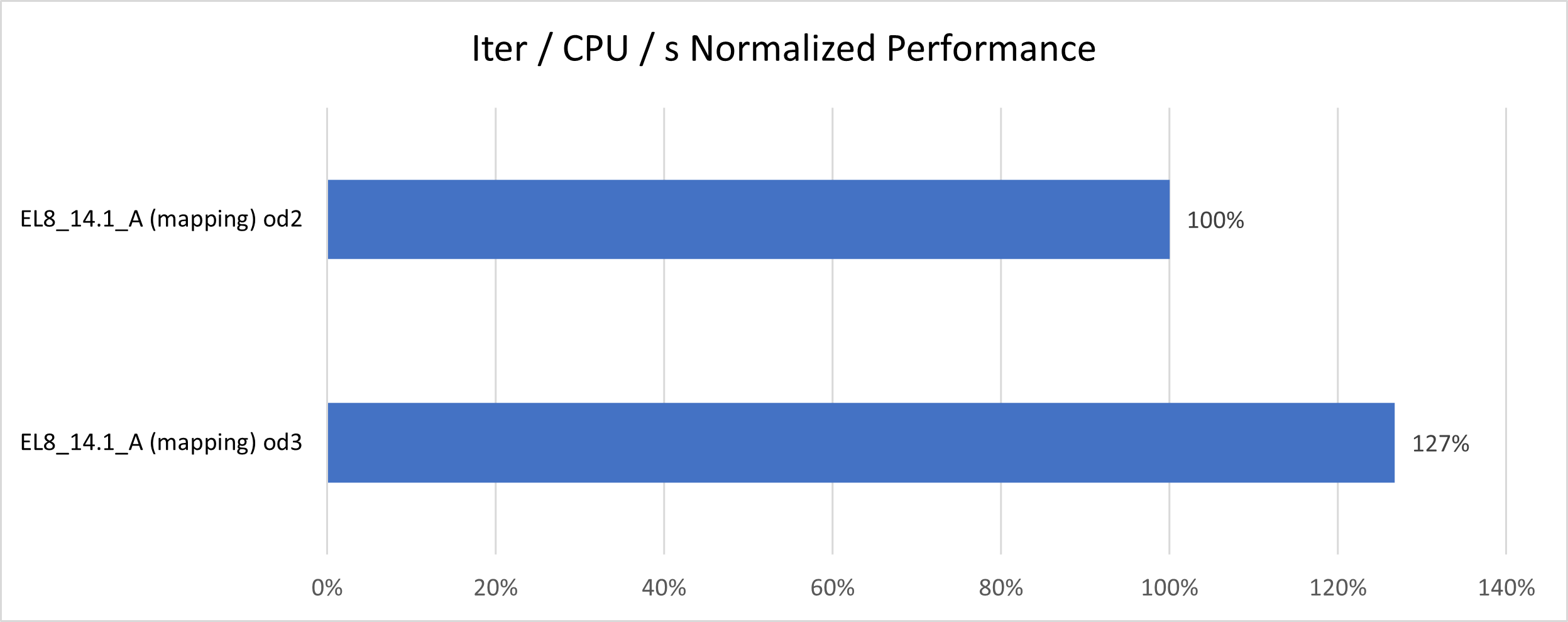
Figure 3: The AMD Genoa CPUs are about 27% faster per core than the AMD Milan CPUs for Fun3D.
That’s not quite as large of an improvement as AMD showed in their launch day marketing materials—but it’s still a nice improvement with no software change required.
Building Software Right: The Key to Optimal Performance
It's not enough to simply get code to execute. Software quality directly impacts performance and spend. Even identical hardware can yield vastly different results depending on the underlying software.
New hardware alone won't solve all problems. Without careful software optimization, even the latest hardware can fall short of expectations. For example, as shown with FUN3D, a seemingly minor change in MPI distribution on a new OS can dramatically slow down simulations.
By prioritizing software quality, we achieve significant performance gains. Our optimizations for FUN3D have led to impressive speedups of 40%--almost 50% more performance improvement than just buying the latest and greatest CPUs. We did the same careful analysis for our Vulcan build, and saw a ~250% speedup.
Let us handle the heavy lifting. We meticulously optimize our supported software builds, ensuring you get the best performance per dollar. Need custom builds? Our team can assist you for a nominal fee.
Existing Customers: Reach out to your account manager to discuss support options to optimize your workloads on our platform!
Prospective Customers: Get a free benchmark on how Corvid HPC can optimize your workflows—fill out the form below or email sales@corvidhpc.com!
Until next time,
-KGM